|
Pers.narod.ru. Наука. Интернет-ресурсы. Часть 1 |
В данной главе работы рассмотрены базовые понятия информатики, связанные с информационными и информационно‑поисковыми системами, основные существующие концепции электронного документооборота, а также критерии оценки эффективности информационно‑поисковых систем и перспективы их развития.
Первичное аксиоматическое понятие информатики выражают термином "информация". Согласно действующему законодательству РФ [1], информация определяется как "сведения о лицах, предметах, фактах, событиях, явлениях и процессах независимо от формы их представления". Информация уменьшает степень неопределенности, неполноту знаний о лицах, предметах, событиях и т. д.
Близкими к понятию информации являются понятия "знания" и "данные". Их, однако, следует различать.
Знания в информатике - вид информации, отражающей опыт специалиста (эксперта) в определенной предметной области, его понимание множества текущих ситуаций и способы перехода от одного описания объекта к другому.
По Д. А. Поспелову [2], для знаний характерны внутренняя интерпретируемость, структурированность, связанность и взаимная активность.
Таким образом, знания - это информация, уже полученная и зафиксированная в мыслительной системе человека или в каком‑либо другом носителе.
Согласно действующему государственному стандарту на термины в области информатики, данные - это сведения полученные путем измерения, наблюдения, логических или арифметических операций и представленные в форме, пригодной для постоянного хранения, передачи и (автоматизированной) обработки.
Под обработкой информации в информатике понимают любое ее преобразование из одного представления в другое, производимое по формальным правилам. В каждом из существующих устройств и систем в той или иной степени происходят сбор и обработка информации.
Представление информации в виде данных требует, как правило, соблюдения определенной структуры данных. Поскольку любые данные при обработке на компьютере представляются в двоичной форме, то есть, в виде совокупности бинарных сигналов со значением 0 или 1, данные разных типов представляются в разных форматах, то есть, с соблюдением определенных правил и последовательности представления единиц информации.
Информация, зафиксированная в компьютерной памяти, по необходимости является данными, поскольку она уже представлена в форме, обработанной компьютерным вводом (машинные коды).
В отличие от "знаний", данные могут не обладать свойствами комплексности и включенности в систему взаимных связей. Данным обычно не свойственны динамические процессы, они стационарно связаны со своим носителем. Так что документ вне процесса коммуникации содержит именно данные, а не знания и не информацию.
Само понятие документа также нуждается в определении.
По законодательству РФ [1], документ - это материальный объект с зафиксированной на нем информацией в виде текста, звукозаписи или изображения, предназначенный для передачи во времени и пространстве в целях хранения и общественного использования. Документ обязательно содержит реквизиты, позволяющие однозначно идентифицировать, содержащуюся в нем информацию.
Таким образом, документ - это не только письменный текст на бумаге, но любой носитель сведений, в частности - музейный экспонат с одной стороны, и файл на сервере, доступный через Интернет - с другой. В большинстве случаев той формой документа, которая предназначена для передачи информации, является письменный текст на естественном языке. Но это не единственный способ фиксировать информацию в документе; в последнее время все большее значение приобретает зрительная и слуховая (аудиовизуальная) информация.
На рубеже XXI века распространилась принципиально новая форма оперативного введения информации в оборот - размещение данных в сети Интернет. Сюда же примыкает практика тиражирования данных на переносимых электронных носителях - сначала на магнитных лентах, затем на сменных дисках и не имеющих вращающихся частей флеш‑носителях. Эти электронные документы невозможно отнести ни к заведомо опубликованным, ни к неопубликованным. Даже выпускаемые от имени солидных издательств электронные документы не имеют пока стандартной формы редакционной подготовки, поскольку такие стандарты еще не вошли в общую практику. С другой стороны, доступность электронных документов неограниченному кругу пользователей не дает права относиться к ним как к личным непубликуемым документам. По степени "физической опубликованности" следует различать следующие виды электронных документов:
· на переносимых носителях (дисках, флеш‑носителях) - подлежат копированию и распространению через торговую и библиотечную сеть наравне с книгами;
· в локальных базах данных - имеют ограниченное распространение в пределах сети доступа к базе данных;
· в общепользовательных сетях (таких, как Интернет) - документы доступны неограниченному кругу пользователей;
· в радио‑ и телевещании - документы существуют только в форме сообщения, широко распространяемого по неконтролируемому кругу получателей.
По характеру содержимого различаются:
· текстовые документы;
· звуковые документы (аудиозаписи, звукозаписи);
· зрительные (визуальные) документы (изображения, видеозаписи);
· мультимедийные документы (аудиовизуальные).
В состав мультимедийных документов разработчики обещают включить компоненты восприятия и другими органами чувств - обонянием, осязанием, вкусом. Подобные формы представления информации в экспериментальном порядке создаются уже сейчас; что дает право говорит об особом классе документов, относящихся к "виртуальной реальности".
Требует пояснений также представление о том, что именно является документом в случае компьютерного представления.
Общепринятое определение гласит, что файл - это поименованная совокупность данных, представленных на машинном носителе информации. Понятие файла применяется в основном к данным, хранящимся на дисках, и поэтому файлы обычно отождествляют с участками дисковой памяти на этих носителях.
Файл - это "минимальная форма" компьютерного документа. Однако, зачастую документы представлены не одним файлом, а достаточно обширным набором файлов, связанных друг с другом логически и операционно. В частности, для доступа к файлам и упорядочения взаимодействия динамически связанных файлов документ бывает снабжен программным обеспечением, также реализованным в виде совокупности файлов. В таком случае документ представляет собой базу данных (БД), а его программное обеспечение - систему управления базой данных (СУБД). В более широком смысле базой данных часто называют просто набор однородных файлов, содержащих информацию по некоторому предмету (не включая в понятие базы данных саму СУБД). В частности, с этой точки зрения базами данных являются сайты в Интернет. В целом, по признаку организации электронные документы делятся на три класса:
· файл;
· база данных (без СУБД);
· полная база данных (содержащая СУБД).
Аналогично печатным изданиям, к электронным документам могут быть применена классификация по их тематическому содержанию, включая выделение основных классов, таких как монографии, сборники, учебники, нормативные источники, рекламные документы и более конкретные подкатегории.
Таким образом, к информационным средствам относятся как традиционные средства накопления и передачи информации - от устных сообщений до библиотек и видеофильмов, так и современные электронные средства представления информации, где любые данные записываются на магнитных или оптических дисках в двоичном коде с соблюдением определенных правил записи. Понятие информации в рассматриваемом смысле оказывается тесно связанными и с общим понятием языка, который является основным средством хранения, накопления и передачи информации.
Методы и средства информатики материализуются и доходят до потребителя в виде новых информационных технологий, под которыми подразумеваются современные виды информационного обслуживания, организованные на базе средств вычислительной техники и средств связи.
Формально информационная технология (ИТ) может быть определена как совокупность методов, производственных и программно‑технологических средств, объединенных в технологическую цепочку, обеспечивающую сбор, хранение, обработку, вывод и распространение информации. Основное назначение ИТ - снижение трудоемкости процессов использования информационных ресурсов.
Одновременно с широким использованием новых информационных технологий появилось понятие "информационная система" (ИС). Согласно [1], ИС - это организационно упорядоченная совокупность документов (массивов документов) и информационных технологий, в том числе с использованием средств вычислительной техники и связи, реализующих информационные процессы. ИС осуществляет сбор, передачу и переработку информации об объекте, снабжающую работников различного уровня информацией для реализации функции управления.
Внедрение ИС повышает эффективность производственно‑хозяйственной деятельности предприятия за счет не только обработки и хранения информации, автоматизации рутинных работ, но и за счет принципиально новых методов управления, основанных на моделировании действий специалистов при принятии решений (методы искусственного интеллекта, экспертные системы и т. п.), использовании современных средств телекоммуникации (электронная почта, телеконференции), глобальных и локальных вычислительных сетей и т. д.
По сфере применения информационные системы классифицируются следующим образом:
· ИС для научных исследований;
· ИС автоматизированного проектирования;
· ИС организационного управления;
· ИС управления технологическими процессами.
Научные ИС используются для автоматизации научной деятельности, анализа статистической информации, управления экспериментом.
ИС автоматизированного проектирования применяют для;
· разработки новых изделий и технологии их производства;
· различных инженерных расчетов;
· создания графической документации (чертежей, схем, графиков и т.д.);
· моделирования проектируемых объектов.
ИС организационного управления предназначены для автоматизации функций административного аппарата. К ним относятся ИС управления как промышленными предприятиями, так и непромышленными объектами (банками, биржами, страховыми компаниями, гостиницами и т.д.) и отдельными офисами (офисные системы).
ИС управления технологическими процессами создают для автоматизации различных технологических процессов.
Развитие информационных технологий настолько тесно связано с возникновением новых моделей бизнеса, что эти процессы нередко воспринимаются как единое целое. Стремление компании повысить эффективность ИС стимулирует появление более совершенных аппаратных и программных средств, которые, в свою очередь, подталкивают пользователей к дальнейшей модернизации ИС.
Совокупность существующих документов образует информационные ресурсы (ИР).
В широком смысле, ИР - это совокупность данных, организованных для эффективного получения достоверной информации.
По законодательству РФ, ИР - это отдельные документы и отдельные массивы документов, документы и массивы документов в информационных системах: библиотеках, архивах, фондах, банках данных, других видах информационных систем.
Если в информационную систему включено в той или иной форме хранилище, из которого выдаются полные тексты документов в рамках единой технологической процедуры ответа на запрос пользователя, такая система называется полнотекстовой информационно‑поисковой системой (ИПС).
Существенными для электронных документов являются два признака, которые не существенны для "классических" печатных документов. Это признаки постоянства и взаимодействия с пользователем. По критерию постоянства можно выделить следующие виды сетевых источников и информационных ресурсов:
· Постоянные документы, содержание которых не меняется со временем, аналогично традиционным документам. К данной категории могут быть отнесены, например, статические Web‑страницы, размеченные в формате HTML;
· Периодически обновляемые документы, содержание которых приводится в соответствие с актуальным положением дел в известные (не обязательно регулярные) моменты времени. Пример реализации данной формы документа - периодически обновляемая новостная лента;
· Непрерывно актуализируемые документы, содержание которых должно отражать текущее развитие некоторого процесса. Как правило, "отражение" это происходит с запаздыванием, объяснимым техническими аспектами, а в качестве примера реализации этой формы документа можно привести интернет‑форум или веб‑чат.
В свою очередь, обновляемые документы могут как пополняться с сохранением всей предыдущей информации, так и заменять старые данные на новые.. В последнем случае пользователь не может вернуться к данным предыдущих состояний документа.
Как документы на переносимых носителях, так и сетевые источники информации можно классифицировать по взаимодействию с пользователем:
· Замкнутые документы, аналогично документам традиционным, не предполагают получения информации от пользователя;
· Диалоговые документы предполагают обязательное получение инструкций от пользователя о форме и порядке предъявления содержимого (компьютерные игры);
· Интерактивные документы предполагают изменение своего содержания путем внесения информации от пользователя. (анкеты, опросы, голосования, конструкторы сайтов и др. средства работы с периодически обновляемыми и непрерывно актуализируемыми документами).
Совокупность гипертекстовых документов, составляющих содержимое www, следует отнести к диалоговым документам. Гипертекст представляет собой базу данных (текстовую либо иную), в которой порядок визуализации того или иного документа задается пользователем путем активации соответствующей ссылки, включенной в текст самого документа. По сути дела, любое взаимодействие пользователя с электронным документом невозможно без элементов гипертекста, но о гипертексте собственно имеет смысл говорить лишь тогда, когда это свойство является существенным и необходимым условием считывания информации документа.
Независимо от формы представления, в документе, помимо содержания, всегда присутствует дополнительная информация о самом документе, которую обобщенно называют метаинформацией. Когда метаинформация представлена в документе специальными средствами форматирования данных, она называется метаданными.
Документы принято разделять на первичные и вторичные.
Первичными документами А.И. Михайлов, А.И. Черный, Р.С. Гиляревский [3] называют документы, отражающие непосредственные результаты научно‑исследовательской и опытно‑конструкторской деятельности. Вторичными называются документы, представляюшие собой результаты аналитико‑синтетической и логической переработки информации, содержащийся в первичных документах. В своей практической деятельности информационные органы к первичным научным документам относят научно‑ технические журналы, брошюры, книги, отчеты о научно‑исследовательских работах. В качестве вторичных научных документов признаются реферативные материалы, реферативные карточки, экспресс информации, диссертации, а также обзорные; статьи и брошюры, библиографические описания, выполненные по материалам информационных изданий.
Можно выделить следующие последовательные информационные процессы, связанные с жизненным циклом документа:
· создание документа,
· издание документа,
· распространение документов,
· хранение документов,
· извлечение информации из документов.
На каждом из указанных этапов жизненного цикла документа, кроме первого, формируются вторичные документы.
Когда первичный документ создан, на втором этапе метаинформация, необходимая для его функционирования, оформляется в качестве самостоятельной выделенной части документа. Для печатных изданий эта часть документа носит название выходных сведений.
Метаинформация отдельных видов документов оформляется по специальным правилам, которые излагают обычно вместе с правилами формирования первичного документа (см. стандарты ГОСТ 7.22 и ГОСТ 7.32). Это обусловлено тем, что общественно установленные правила создания документа, имеющего общественную значимость, предполагают наделение его метаинформацией обеспечивающей общественное функционирование документа.
В процессе распространения документа (третий этап) необходимо иметь информацию о первичном документе в качестве отдельного объекта, чтобы использовать именно ее, не входя в основное содержание документа. Кроме того, знакомство с содержанием документа может быть запрещено или ограничено.
Для опубликованных и многих непубликуемых документов составляют так называемое библиографическое описание. Этот вторичный документ предназначен для того, чтобы сжато предоставить сведения о форме и содержании первичного документа. Основой библиографического описания служат выходные сведения.
К библиографическим описаниям можно сформулировать общие требования, не зависящие от содержания и вида описываемых документов, а также от сферы их применения:
· краткость;
· достаточно полное и точное описание содержания и формы первичного документа;
· однозначная, безошибочная и быстрая идентификация первичного документа по содержащимся в описании сведениям.
На этапе хранения документов возникает необходимость инвентаризации и систематизации документальных фондов. При работе с традиционными "бумажными" документами эта цель достигается путем сведения библиографических описаний в каталоги и указатели, представляющие собой новый вид вторичных документов. Среди этих библиографических пособий можно выделить наиболее важные виды информационных работ.
Каталог представляет собой перечень библиографических описаний с указанием места хранения первичного документа. Каталоги появляются везде, где собирается более или менее значительное количество хранимых документов.
В каталоге описания располагаются в определенном порядке, облегчающем поиск нужного документа. Порядок расположения документов в каталоге - важнейшая характеристика, определяющая информационную работу. Другой, не менее важной характеристикой, является материальная форма каталога. В традиционной технологии известны каталоги в списочном и картотечном виде [4].
Очевидны преимущества и недостатки того и другого вида каталогов. Преимущества списочного каталога - компактность, удобство пользования. Преимущества картотечного каталога - удобство его пополнения, исправления и реорганизации. В настоящее время эти классические формы каталогов замещаются электронными каталогами, совмещающими в себе преимущества обоих видов традиционных каталогов и обладающими дополнительными возможностями.
Прежде, чем подробнее обсудить проблемы, связанные с информационными работами над электронными документами, приведем краткие сведения об устройстве традиционных каталогов.
По способу группировки описаний каталоги подразделяются на алфавитные, систематические и предметные.
В алфавитном каталоге описания документов располагаются в алфавитном порядке заголовка описания (фамилии автора, наименования организации, заглавия документа). Часто в алфавитный каталог включаются дубликаты описаний, упорядоченные как по фамилии автора, так и по наименованию либо организации. Алфавитный каталог дает однозначный ответ на вопрос о наличии или отсутствии определенного документа.
Для облегчения подбора документов по их содержанию и удовлетворения тематических запросов создаются систематические каталоги. В них описания документов группируются по отраслям знания, с которыми связано содержание документа. Систематический каталог раскрывает тематическое содержание документального фонда
Для ознакомления с систематическим каталогом необходимо знать, какой классификации отраслей знания придерживается данный каталог. В больших каталогах документы подразделяются не только на классы, соответствующие крупным отраслям знания, но в пределах каждой отрасли делятся по подклассы, а в отдельных подклассах - по проблемам и направлениям. Систематические каталоги должны быть снабжены описанием этой классификационной системы, представляющим собой вторичный документ второго порядка (документ, содержащий метаинформацию о вторичном документе). Схема, по которой систематизируются тематические каталоги, называется библиографической классификацией.
В предметном каталоге состав фонда документов также раскрывается по их содержанию, но описания документов группируются не по отраслям знания, а по наименованиям конкретных объектов, описываемых в документах. Слово или словосочетание, обозначающее какой‑либо предмет рассмотрения или понятие, используемое для отражения содержания документов и группировки описаний в каталоге, называется предметной рубрикой. В предметном каталоге разделы, соответствующие предметным рубрикам, располагаются в общем порядке предметных рубрик (обычно алфавитном). В пределах сложных рубрик могут вводиться дополнительные подразделы, наименования которых включают общую предметную рубрику и различаются уточняющими словами.
Предметные каталоги особенно удобны для поиска в документальных фондах по прикладным вопросам, где основой документов являются описания конкретных изделий и процессов, а не абстрактных знаний.
В современных электронных каталогах функции всех трех типов традиционных каталогов совмещаются в одном компьютерном документе представленном в виде базы данных. Тем не менее, в них также можно выделить подсистемы, выполняющие функции выше рассмотренных каталогов. База данных представляет собой совокупность файлов, связанных программными средствами. В базах данных, как правило, присутствуют индексные файлы, содержащие списки всех заголовков библиотечных описаний, предметных рубрик, областей знания, причем каждому элементу списка сопоставлены адреса документов или описаний. Эти списки выступают как аналоги алфавитного, предметного и систематического каталогов соответственно.
Специфической задачей является извлечение полезной (ценной) информации из документов и баз данных.
Речь может идти о двух видах извлечения ценной информации: либо об извлечении информации, наиболее ценной с общепринятой точки зрения, либо об извлечении информации, ценной с точки зрения конкретной потребности отдельного пользователя [5].
В первом случае извлечение информации сводится к сокращенному изложению документов.
Традиционно выделяют такие формы информационной работы по извлечению сведений из документов, как аннотация, реферат, рецензия, реферативный журнал (сборник), обзор [6].
В случае автоматической обработки текста с целью аннотирования или реферирования естественно предположить, что у выполняющего данную работу автомата знания о предметной области должны быть "заранее встроены" в форме, сопоставимой с формой представления входной информации.
Анализируя имеющиеся информационные системы, можно выделить несколько подходов к решению этой задачи. Первый, наиболее естественный - вложить в автоматическую систему реферирования список терминов, относящихся к предметной области. В этом случае методика реферирования состоит в выделении из документа предложений, включающих эти термины.
Трудности такого подхода очевидны - размытость существующих терминологических полей, их недостаточная привязка к определенным знаниям, постоянное появление новых терминов, нетерминологическое использование имеющихся. Альтернативный подход - автоматический поиск знаний общего характера, основанный на языке документа. Например, из научного документа следует прежде всего извлечь постановку задачи, методы ее решения, основные выводы и результаты. В тексте документа соответствующие разделы работы должны быть отмечены ключевыми словами. Трудность этого подхода - чрезвычайное богатство средств выражения естественного языка. Поэтому неоднократно разрабатывались стандарты, призванные как ограничить языковые средства, применяемые в деловых документах, так и стандартизовать саму форму документа, в пределе превратив его в таблицу с ответами на заранее заданные конкретные вопросы. Именно подобная методология применяется во многих существующих банках знаний и экспертных системах.
Существуют и другие подходы к автоматическому реферированию, но их общие недостатки состоят в том, что во‑первых, они в любом случае приводят к тексту, трудному для восприятия человеком, во‑вторых предполагают ввод в машину полных текстов документов, что делает бессмысленной саму задачу реферирования.
Итак, одним из путей информационного обслуживания является компрессия первичных документов в форме вторичных, в которых выявлена наиболее важная (с общепринятой точки зрения) информация, которая на регулярной основе доводится до пользователей.
Второй путь состоит в том, чтобы в документах отыскивать информацию, важную в конкретном случае для удовлетворения текущей потребности пользователя, возникшей в данный момент.
В этом случае пользователь должен сформулировать информационный запрос. А информационная система, проанализировав имеющийся документальный фонд, должна найти в нем документы, соответствующие запросу, и выдать их пользователю. Эта процедура, называемая информационным поиском, является важнейшим видом информационной деятельности наряду с упомянутой выше аналитико‑синтетической обработкой документов.
При этом возникают два связанных вопроса. Для того чтобы изложить свою информационную потребность в форме, приемлемой для автоматизированной обработки, нужен особый язык запросов. С другой стороны, документы должны быть заранее описаны по их содержанию на языке, понятном неспециалисту - языке описания документов. В связи с этим возникло понятие "информационно‑поисковый язык" (ИПЯ), понимаемый как совокупность средств и методов описания документов и запросов, а также процедур сопоставления этих описаний с целью отыскания документов, удовлетворяющих информационную потребность пользователя [7].
Правила выбора слов для составления и упорядочения библиографических описаний задаются стандартами, утверждаемыми на национальном или международном уровне, в частности, российским государственным стандартом ГОСТ 7.1. Стандарты устанавливают правила выбора слов, правила соединения их в составе описания, правила расположения описаний в каталогах.
Поиск по библиографическим данным для современной компьютерной системы представляет собой довольно простую задачу. Для этого достаточно создать индексный файл, состоящий из упорядоченного перечня элементов библиографического описания, по которым может идти поиск (поисковые элементы), где каждому элементу сопоставлен адреса документов, имеющих этот поисковый элемент в своем библиографическом описании. Индексный файл структурируется таким образом, чтобы программа поиска могла быстро обнаруживать в нем заданный элемент. Конкретный способ упорядочения определяется из соображений оптимизации программного обеспечения, классическая структура поискового индекса многократно описана в литературе [8, 9]. Найдя в индексном файле элемент описания, заданный пользователем, система сразу же получает список адресов релевантных документов и может выдать их пользователю.
Современные поисковые машины уже "научились" учитывать грамматику естественного языка и в своем индексном файле объединяют записи словоформ, относящиеся к одной лексеме (слову с одним значением, но в разных формах, склонения или спряжения), что несколько уменьшает объем индексируемой информации.
На индексных файлах легко осуществлять поиск по сложным запросам, когда пользователь задает несколько условий поиска, связанных логическими отношениями. Например, нужно найти произведения автора 1 в соавторстве с автором 2 и дополнительно произведения автора 3, изданные в определенных издательствах. Для исполнения подобного запроса достаточно из списка документов, полученных по первому поисковому элементу, удалить адреса, отсутствующие в списке, связанном с именем второго автора, добавить адреса документов из списка, связанного с именем второго автора, и удалить из них адреса, отсутствующие в списке, связанном с наименованием издательств. Подобные операции легко моделируются с помощью операций булевой алгебры.
Более сложна задача поиска документов по их содержанию. Заглавие документа редко становится поисковым элементом описания. Основным способом раскрытия содержания является отнесение документа к той или иной области знания или сфере деятельности. Выбор областей знания основывается на философской классификации наук, а выбор сфер деятельности - на структуре общественной жизни. Но конкретный список классов, на которые следует разделить документы, определяется практическими потребностями поиска того или иного содержания, а также объемом документального фонда - чем этот фонд обширнее, тем подробней должно быть классификационное деление.
Кратко охарактеризуем основные классификационные системы, принятые в международной практике.
В результате промышленной революции, в конце XIX века возникло представление о научном знании как важной производственной силе, и была поставлена задача инвентаризации всего накопленного человечеством знания. Для решения этой задачи бельгийские библиографы Otlet и Lafontaine инициировали создание специальной международной организации, которая называлась Международная федерация по информации и документации (сокращенно - МФД, или ФИД от французского FID - Federation Internationale d'Information et Documentation). В рамках этой организации была разработана и всеобщая схема классификации знаний, которая получила наименование "Универсальная десятичная классификация" (сокращенно - УДК). С тех пор уже более 100 лет данная классификационная система успешно развивается и применяется для систематизации как библиотечных фондов, так и автоматизированных информационных служб.
Краткое описание структуры УДК наглядно иллюстрирует все проблемы и приемы организации информационно‑поисковых языков классификационного типа.
Согласно УДК, вся совокупность знаний делится на 10 главных классов:
0 Общие вопросы науки и информационной деятельности
1 Философия, логика, психология
2 Религия, богословие
3 Общественно‑экономические науки
4 (Свободный резервный класс)
5 Естественные и точные науки
6 Прикладные области знания (включая медицину, технику и сельское хозяйство)
7 Искусство, развлечения, спорт
8 Язык и литература
9 История и география.
Каждый класс, в свою очередь, делится на 10 или менее подклассов. Подклассы делятся дальше до любого необходимого уровня подробности.
Каждое деление обозначается десятичной цифрой, а цифры последовательных делений соединяются в одном индексе, где первая цифра обозначает номер деления на главные классы, вторая - номер подкласса первого уровня, третья - подкласс второго уровня, и так далее. Для облегчения зрительного восприятия индекса через каждые три цифры ставится точка.
Кроме тематической характеристики, УДК позволяет отразить в индексе дополнительные особенности оформления документа или его содержания. С этой целью в индекс добавляются определители данных особенностей, обозначенные специальными символами:
= - язык документа (=111 английский, =161.1 русский)
(0 ) - форма, назначение документа (закон, учебник, справочник и т.п.)
(4/9 ) - страна, к которой относится содержание документа: (4) Европа, (470) Россия в целом, (5) Азия, (571) Сибирь и Дальний Восток России
" " - время, к которому относится содержание документа: "2007" нынешний 2007 год, "20" двадцать первый век, "19" двадцатый век, "0" первое тысячелетие нашей эры, "-0" первое тысячелетие до нашей эры
Кроме того, допускается комбинировать в одном индексе коды разных классов для указания на документы, имеющие отношения к различным отраслям знания.
Применение этого языка в информационной системе происходит многократно, на разных стадиях информационного процесса.
На этапе создания системы необходимо выбрать в УДК те классы, которые нам потребуются. При этом задача состоит не только в отсеве "лишних" классов, но также в конструировании комбинированных классов, точно выражающих конкретные информационные потребности.
На этапе ввода документа его требуется отнести к тому или иному классу каталога. Для этого нужно определить содержание документа, его тематику, и обозначить эти данные теми или иными индексами УДК (процедура индексирования документа). Индексирование должно быть всесторонним, как того требует международный стандарт ИСО 5963‑85 и отечественные стандарты ГОСТ 7.66 и ГОСТ 7.59. На этапе индексирования документов также могут создаваться комбинированные классы, а документ может попасть в два и более классов заранее установленного каталога.
На этапе индексирования запросов выявляются те разделы каталога, в которых могут содержаться документы, необходимые пользователю. Эти разделы обозначаются соответствующими индексами УДК, которые также могут быть комбинированными, когда запрос не укладывается в имеющуюся сетку классов.
На этапе сопоставления индекса запроса с индексом раздела каталога может выявиться несовпадение индексов, которое еще не означает, что в хранилище нет необходимых документов. Соответствующими запросу признаются документы, индексы УДК у которых не посимвольно совпадают с индексом запроса, а совпадают по своим значащим частям.
В автоматизированных системах эти процедуры выполняются автоматически с помощью специально разрабатываемого программного обеспечения. Однако, интеллектуальные алгоритмы индексирования весьма сложны в реализации, поэтому еще в 60‑х годов XX века разработчики первых автоматизированных ИПС пришли к выводу о нецелесообразности применения УДК. Требовалась более простая система классификации, без сложных правил, требующих интеллектуального подхода. Подобная система была разработана и получила широкое распространение: речь идет о государственном рубрикаторе научно‑технической информации (ГРНТИ) [10].
Схема ГРНТИ состоит из 69 главных разделов, соответствующих научным дисциплинам и отраслям народного хозяйства. Они сгруппированы в 4 блока: общественные науки, точные и естественные науки, технические науки (отрасли хозяйства), комплексные проблемы. Каждый главный раздел поделен на подразделы, которых может быть до 100, обычное число подразделов от 5 до 20. Подразделы делятся на рубрики третьего уровня таким же образом. Дальнейшее деление рубрик не предусмотрено. Всего в ГРНТИ около 7000 рубрик. При индексировании документов по ГРНТИ комбинирование рубрик не предусмотрено. Однако при необходимости один документ может быть отнесен к двум и более рубрикам.
В западных странах наряду с УДК применяются другие классификационные системы. Во‑первых, это десятичная классификация Дьюи, разработанная американским библиографом Мелвилом Дьюи. Она имеет статус национальной библиографической классификации США и применяется также во многих библиотеках других странах. Преимуществами ДКД отчасти являются ее недостатки: это менее развитая классификация, которой проще пользоваться, поэтому она находит поддержку у разработчиков автоматизированных информационных систем. Также популярна на Западе "Классификация Библиотеки Конгресса США".
Существующие информационно‑поисковые языки включают не только словарные компоненты, но и правила, обеспечивающие процедуры применения словарей. Запуск этих процедур осуществляется специальными управляющими кодами, которые вместе с алгоритмами процедур, соответствующих этим командам, составляют языки описания данных (ЯОД) и языки манипулирования данными (ЯМД). Первые из них (ЯОД) содержат команды записи определенных значений в информационные файлы системы в соответствии с некоторыми характеристиками документов или запросов. ЯМД содержат команды двух видов - команды поиска информации и команды отображения информации для пользователя. Совокупность команд поиска информации называются также языком запросов. В настоящее время фактическим стандартом является язык запросов SQL (Structured Query Language - язык структурированных запросов).
Описанные информационно‑поисковые языки классификационного типа наряду с языками библиографических данных являются основой технологии информационного поиска. Но перспективы развития информатики в настоящее время связывают с языками другого типа, которые мы рассмотрим далее.
Кроме алфавитных и систематических каталогов в электронных библиотеках распространены и предметные каталоги. Сущность предметного каталога заключается в том, что содержание документа кратко формулируется при помощи одного или нескольких типовых ключевых слов, получивших название предметных рубрик. Затем предметные рубрики располагаются по алфавиту и под каждой из них как под заголовком собираются библиографические описания документов. Составление предметных рубрик и распределение по ним документов называется предметизацией. Задача предметизации обычно состоит в том, чтобы указать главный объект рассмотрения в документе, возможно, также основные его аспекты и основные отношения к другим предметам.
В отличие от библиографических классификаций предметизация распределяет документы по предметам или понятиям, не соотнося их с какими‑либо областями знания. Это различие делает классификационный и предметный принципы организации документов независимыми и дополняющими друг друга, предназначенными для поиска документов по разным типам запросов. Предметизация дает возможность собирать в одном месте документы по таким комплексам как конкретный материал, свойство, изделие, явление природы или общества, род деятельности, географическое понятие и т. д., собирая под каждым предметным заголовком весь массив знаний, безотносительно к тому, какой области науки эти знания принадлежат.
Другим отличием предметизации от классификации является то, что заранее составленный список предметных заголовков не ограничивает подробности анализа содержания документа. Если документ посвящен вопросу, не отраженному в списке предметных заголовков, всегда имеется возможность сформулировать новый заголовок самостоятельно. Обычно же при выборе предметной рубрики для документа руководствуются заранее составленным списком предметных заголовков. Но не представляет труда внести в него вновь образованную предметную рубрику, которая займет свое надлежащее место, определяемое алфавитным порядком. Этого обычно не удается делать в языках классификационного типа, где введение новых классов зачастую влечет преобразование большой части классификационных связей.
У каждого предметного заголовка могут в принципе быть подзаголовки, делящие документы в рубрике на подрубрики. В некоторых случаях к предметному заголовку могут быть даны ссылки на другие рубрики, где могут находиться документы по сходному предмету. Таким образом, в списке предметных заголовков одна запись может иметь довольно сложный характер.
Традиционная каталожная техника не позволяет раскрывать содержание документа предметными рубриками с достаточной полнотой.
Современная компьютерная техника существенно уменьшает ограничения по объему каталогов и снижает трудоемкость их составления. Поэтому получила распространение идея приписывать документам все ключевые слова, используемые в документе, и в электронном каталоге иметь индексный файл записи адресов документов, использовавших каждое ключевое слово.
Под ключевыми словами в данном случае понимаются наиболее существенные для выражения содержания документа полнозначные слова и словосочетания, обладающие назывной (номинативной) функцией. Поиск документа при этом должен происходить, как правило, не по одному ключевому слову (и не по одной предметной рубрике, как в случае языка предметных рубрик), а по формулировке поисковой потребности, содержащей ряд ключевых слов, полно описывающих тему поиска. В процессе поиска по записям индексного файла, соответствующим ключевым словам запроса, должны производиться логические операции над множествами адресов документов.
Ключевые слова образуют новый способ описания и поиска документов - язык ключевых слов - индексно‑поисковый язык (ИПЯ) ключевых слов, который сливается с языком библиографических данных в единый программный комплекс с едиными процедурами поиска.
Описанная организация языка ключевых слов позволяет существенную экономию ресурсов памяти по сравнению с языком предметных рубрик.
Язык ключевых слов обладает очевидными недостатками - прежде всего, в нем индексируются не понятия, а формально отличные термины, что может сделать невозможным, например, поиск синонимов или, напротив, слишком расширить область поиска в случае использования многозначных ключевых слов.
Для преодоления этих недостатков "понятие" может быть задано как совокупность всех способов обозначения его в текстах, то есть, как множество синонимов. Для этого в автоматизированную систему вводится словарь, содержащий синонимы, эквивалентные и идиоматические выражения:
Компакт‑диск = CD = CD‑ROM
Компьютер = вычислительная машина = ЭВМ
Языкознание = лингвистика = языковедение
Одно из эквивалентных выражений выбирается как нормативное слово, допущенное для использования, а остальные синонимы служат справочным материалом и подлежат замене на нормативное обозначение понятия.
Идею использовать при индексировании документов и запросов словари синонимов предложил американский математик C. Mooers в середине прошлого века. Совокупность синонимов, обозначающих одно понятие, он назвал "дескриптор" ("описатель"). Расширительно дескриптором называют также тот нормативный синоним, который в системе заменяет собою остальные синонимы. Последние получили наименование "аскрипторы" ("не‑описатели ").
В дальнейшем было предложено вводить в дескрипторный словарь другие отношения - отношения понятий, описываемых дескрипторами как целое, а сам словарь получил название информационно‑поискового тезауруса. При этом в словаре ключевых слов (дескрипторов) содержатся все слова, допущенные для использования при индексировании.
Информационно‑поисковый тезаурус (ИПТ) - это словарь терминов определенной области знания, в котором между терминами зафиксированы путем ссылок смысловые связи понятий, отражающие взаимодействие (отношения) объектов и явлений действительности. В последнее время распространилось наименование этого понятия также термином "онтология". Системы описания документов и запросов с помощью дескрипторов и информационно‑поисковых тезаурусов называют информационно‑поисковыми языками дескрипторного типа, или дескрипторными ИПЯ [11].
Функционирование информационной системы с встроенным ИПЯ дескрипторного типа происходит следующим образом: документ подвергается анализу на содержание в нем терминов, включенных в тезаурус. Термины, обнаруженные в документе, приписываются ему аналогично классификационному индексу. В идеале документ проверяется на вхождение каждого термина из тезауруса. Этот принцип индексирования документов дескрипторами тезауруса называется координатным или дескрипторным индексированием. Если предел классификационного индексирования - определить "единственно правильное" место документа в каталоге, то для дескрипторного индексирования этот предел - определить отношение документа ко всем включенным в ИПТ терминам‑координатам.
Существенно то, что термин может характеризовать документ не только фактом своего присутствия в нем, но также и "важностью", информационным весом термина в документе. Веса терминов могут вычисляться по числу их употребления в данном документе, а также назначаться по вхождению в заглавие и другие важные элементы документа. Некоторые слова могут также иметь собственные особенности, влияющие на их вес. Так, существенно облегчают автоматизированный анализ документов списки "запрещенных" или стоп‑слов, куда входят слова грамматического характера, а также слова со слишком неопределенным значением, заведомо не способные описывать тематику документа и не входящие в число дескрипторов тезауруса. Веса дескрипторов также могут назначаться путем экспертного анализа их смысловой значимости в данном документе.
При анализе документов имеет значение также учет связности дескрипторов, указывая, что слова употребляются рядом в идиоматическом смысле, употребляются в одном предложении или абзаце и т.д. Можно указывать расстояние между словами в числе промежуточных слов, что в некоторой степени отражает их смысловую связь. Применяются и другие указатели связи.
При автоматизированном интеллектуальном анализе документа возможен учет смысловой роли дескрипторов, например, такие ключевые дескрипторы как "главный предмет рассмотрения", "характеристика предмета", "цель исследования", "результат", "условия", и т.д. могут служить указателями роли.
В результате индексирования документа он приобретает свое описание в виде перечня дескрипторов, дополненных их весами, связями и указателями роли. По этому описанию внутри системы составляются каталоги, служащие для поиска документов и выдачи их из базы знаний. Эти описания называют поисковыми образами документа (ПОД). На данную работу приняты ГОСТ 7.66 (координатное индексирование документов) и ГОСТ 7.52 (поисковый образ на машинных носителях). В полном объеме эту работу можно осуществить, когда речь идет об ограниченном потоке данных, таких как поступления новых специальных документов в архив или базу данных предприятия с узкой сферой деятельности. Такие системы интеллектуального индексирования получили некоторое распространение уже с 60‑х - 70‑х гг. XX в. [12].
Разумеется, процедура выявления дескрипторов в документе требует разработки довольно сложного программного обеспечения, решающего такие задачи, как идентификация одного и того же слова в различных грамматических формах, распознавание словосочетаний как форм выражения одного понятия, разрешения проблем многозначности слов и синонимии [13].
Поскольку внутри информационной системы документ представлен своим поисковым образом, запрос пользователя на поиск информации должен быть составлен в сопоставимой с документом форме.
Лишь в этом случае сравнение поисковых образов имеющихся документов с поисковым образом запроса (ПОЗ) даст ответ на соответствие документа запросу. ПОД и ПОЗ одинаково представляются как перечни дескрипторов с возможным указанием весов, ролей и связей. Но сравнение ПОД и ПОЗ предполагает также, что задан критерий смыслового соответствия. В какой степени должен ПОЗ совпадать с ПОД? По каким именно правилам ПОЗ, содержащий N дескрипторов, сопоставляется с ПОД, в котором дескрипторов N+K?
Ситуация усложняется тем, что в различных случаях информационным потребностям пользователя могут отвечать различные критерии смыслового соответствия. Совокупность ПОЗ и критерия смыслового соответствия называют поисковым предписанием. В простейшем случае и в большинстве реально существующих систем автоматизированного поиска критерий смыслового соответствия сводится к объединению дескрипторов булевскими операциями (найти документы, в которых встречаются все дескрипторы или хотя бы один из них). Очевидно, что подход этот несовершенен. Рассмотрение в следующей части монографии существующих на сегодня языков запросов позволит оценить перспективы их развития.
В целом дескрипторный информационно‑поисковый язык представляет собой сложный комплекс, включающий в себя следующие составные части:
· информационно‑поисковый тезаурус, представляющий внутри информационной системы модель онтологии предметной области поиска;
· правила представления в поисковых образах объекта информационного поиска как фрагмента онтологической модели, заданной в тезаурусе;
· массив поисковых образов документов, где каждый ПОД представляет собой модель понятийного содержания документа, соотнесенную с предметной областью через ее модель, заданную в тезаурусе;
· правила формирования поискового предписания, выражающего искомые сведения дескрипторами тезауруса;
· правила определения критерия смыслового соответствия ПОД и ПОЗ.
Этот набор компонентов дескрипторных ИПЯ позволяет рассматривать их как потенциально мощный инструмент смыслового поиска информации. Реальная эффективность этого инструмента определяется степенью развития каждого из пяти компонентов. В настоящее время можно говорить о начальном периоде разработки и эксплуатации дескрипторных языков.
Следует отметить, что наиболее перспективным путем развития представляется использование на базе новых компьютерных технологий уже существующих нормативных документов в данной предметной области. Важнейшими из них являются существующие международные и государственные стандарты.
Российские государственные стандарты:
· ГОСТ 7.25‑2001 Тезаурус информационно‑поисковый одноязычный. Правила разработки, структура, состав и форма представления;
· ГОСТ 7.24‑90 Тезаурус информационно‑поисковый многоязычный. Состав, структура и основные требования к построению;
· ГОСТ 7.47‑84 Коммуникативный формат для словарей информационных языков и терминологических данных. Содержание записи;
· ГОСТ 7.52‑85 Коммуникативный формат для обмена библиографическими данными. Поисковый образ документа;
· ГОСТ 7.66‑92 Индексирование документов. Общие требования к координатному индексированию;
· ГОСТ 7.74‑96 Информационно‑поисковые языки. Термины и определения.
Международные стандарты:
· ИСО 2788:1986 Документация. Руководство по построению и разработке одноязычных тезаурусов;
· ИСО 5963:1985 Документация. Методы анализа документов, определения их темы и подбора индексирующих терминов;
· ИСО 5964:1985 Документация. Руководство по построению и разработке многоязычных тезаурусов;
· ИСО 6156:1987 Формат для обмена терминологическими и/или лексикографическими данными (MATER).
Подробнее вопросы, связанные с автоматическим индексированием информации и критериями оценки эффективности существующих и разрабатываемых информационных систем, будут раскрыты в следующем разделе монографии.
Возможности современных компьютерных систем позволяют отказаться от ограничения определенным набором слов, указанных в тезаурусе, и включать в автоматически формируемый поисковый образ документа все его лексемы, за исключением отдельно сформированного списка стоп‑слов. Именно по этому принципу работает большинство существующих поисковых машин в Интернет. Однако, не имея тезауруса, такие поисковые машины не могут осуществлять смысловой анализ текста, распознавать составные термины, представленные словосочетаниями, многозначные слова и синонимы, логические связи понятий. Описанное упрощенное координатное индексирование произвольными однословными дескрипторами принято называть языком пословного индексирования. Программа‑crawler (см. п. 2.2), просматривая доступное по ссылкам содержимое Web‑страниц, выделяет из текстового содержимого каждого сайта отдельные словоформы, удаляет неинформативные слова из стоп‑словаря, а все остальные слова записывает во внутренний словарь с указанием для каждого слова адресов страниц, на которых оно употреблено. Несложно дать грубую оценку требуемых при этом ресурсов памяти. Оценив объем современного делового национального языка в 100 тысяч лексем, распространенность одной лексемы в 10 миллионов адресов, а длину одного адреса в 100 символов, получаем объем данных 1014 символов, то есть, 100 млн. мегабайт или 100 тысяч терабайт. Подобный объем данных обрабатывается американской системой наблюдения за Землей в течение 100 дней. Этот период можно считать и верхней оценкой того времени, в течение которого сведения о конкретном сайте становятся известны поисковой системе.
Разумеется, развитые поисковые машины учитывают грамматику естественного языка, объединяя в индексном файле записи о словоформах, относящиеся к одной лексеме, что позволяет как "косвенно" находить объект запроса в различных падежах, так и сокращать индексный файл за счет объединения записей словоформ. Тем не менее, эффективность пословного индексирования остается достаточно низкой, а основной его проблемой - реализация лексического, а не семантического поиска. Концепция информационно‑поискового тезауруса (ИПТ), в последнее время возрождающаяся и активно обсуждаемая под терминами "семантический веб" и "онтологии", как будет показано ниже, дает пути к принципиальному решению проблемы поиска информации "по смыслу".
Как уже указывалось, первые правила разработки и форма представления ИПТ была определена стандартом ГОСТ 7.25 и аналогичными стандартами других стран в 70‑х годах XX в. Форма представления ИПТ на машинно‑читаемых носителях была документирована в 80‑х годах стандартом ГОСТ 7.47 и сходными зарубежными и международными стандартами. Форма представления онтологий в настоящее время определяется разработкой в рамках профессиональной ассоциации 3WC стандарта OWL (Ontology Web Language), де факто становящегося международным стандартом.
В первую очередь, после определения предметной области разрабатываемого ИПТ, стандарт предполагает создание словаря терминов (ключевых слов) данной предметной области
Стандарт уточняет, какие именно ключевые слова могут входить в тезаурус: требования сводятся к тому, что они должны представлять вполне ясные понятия, могут быть однословными и словосочетаниями, а также компонентами сложных слов. Слова и словосочетания должны быть приведены к единому (словарному) виду. Многозначные слова должны быть снабжены метками, определяющими в каком смысле слово используется в данном тезаурусе.
Целесообразно иметь также словарь меток, определяющих базовые понятия для разрешения многозначных терминов (такие термины, как процесс, место, вещество и т.д.)
Для дескрипторов определены отношения синонимии, для аскрипторов (неиспользуемых в поисковом образе ключевых слов) могут быть установлены связи к дескрипторам, заменяющим аскриптор либо альтернативно, либо совместно в качестве комбинации дескрипторов.
В тезаурусе фиксируются родо‑видовые отношения понятий, устанавливающих связь между двумя дескрипторами, если объем понятия одного входит в объем другого.
Стандартом также предусмотрено родственное отношение "часть‑целое", как вхождение друг в друга не понятий, а обозначаемых ими объектов.
Наконец, предусмотрено установление ассоциативных связей между дескрипторами, значения которых "напоминают" друг друга. В психологии различают два главных вида ассоциаций - по смежности и по сходству. Стандарт составления онтологий также предусматривает возможность указания вида ассоциации. Ассоциация по смежности устанавливается между дескрипторами, когда обозначаемые ими объекты имеют общие части (например, общее пространство). Ассоциация по сходству устанавливается, когда значения дескрипторов имеют общие формы.
Стандарт предполагает возможность введения в тезаурус других отношений, важных для конкретной практики, при условии их точного описания.
Итак, ИПТ представляет собой словарь терминов, в котором прежде всего указаны ссылки от терминов к их синонимам (эквивалентам), к обобщающим (родовым) и к частным (видовым) понятиям.
Так, в отличие от лексического поиска, система, содержащая подобный словарь, по запросу с термином "программное обеспечение" способна присоединить в выдачу документы, содержащие синонимы ("софт"). Возможно также присоединение по видовым терминам ("web‑программирование", "прикладное программирование"), терминам обобщающих понятий ("программирование", "кодирование") и ассоциативным понятиям ("информатика", "обработка данных").
Добавив в тезаурус другие базовые смысловые отношения терминов, такие как часть - целое, причина - следствие, свойство - носитель, процесс - инструмент и т.п., мы имеем возможность формулировать поисковые образы логически сложных запросов, например, "найти документы, в которых объект A является носителем свойства B при условии C".
Еще более существенно то, что в системе, обладающей развитым ИПТ, появляется возможность автоматизации логических выводов: если объект или явление, описанные в документе, характеризуются множеством дескрипторов L, то это явление должно содержать характеристики, указанные множеством Q(L) обобщающих дескрипторов и дескрипторами следствия, а также может содержать характеристики, указанные множествами видовых и ассоциативных дескрипторов. Если на такую возможность указывают сразу несколько дескрипторов, она становится более вероятной (релевантной запросу).
Теоретическая возможность построения подобных логических выводов свидетельствует о том, что система с развитым ИПТ может быть отнесена к базам знаний. Таким образом, можно постулировать, что текущее развитие информационной теории и практики приводит информационные системы к рубежу, за которым встраивание в них развитых и стандартизованных информационно‑поисковых тезаурусов приведет к технологиям искусственного интеллекта.
Кратко остановимся на существующих критериях оценки эффективности интеллектуальных информационно‑поисковых систем.
Информационный запрос пользователя представляется поисковой системе в виде поискового образа запроса, представляющего собой формализованный перечень терминов. Кроме того задается формальный критерий соответствия документа запросу. Поисковый образ запроса вместе с критерием соответствия составляют поисковое предписание. Информационная система в ответ на запрос, выполняя поисковое предписание, выдает некоторую совокупность документов.
Однако не все найденные документы удовлетворяют информационной потребности пользователя. Как правило, они лишь формально соответствуют поисковому предписанию. Документы, действительно соответствующие потребности пользователя, называются пертинентными. Поскольку информационная потребность представляет собой весьма сложное психическое явление, проблема повышения степени пертинентности поиска весьма трудна не только для разрешения, но даже для формализованной постановки задачи.
Проще определить релевантность найденного документа как меру соответствия его документированному запросу. Однако, и автоматизированная оценка релевантности возможна лишь в техническом аспекте (формальное вхождение элементов поискового предписания в документ), но не семантическом (соответствие запроса потребности пользователя).
Для организации поиска документов система должна уметь оценивать релевантность априори, чтобы вывести в результатах поиска именно релевантные документы. А для определения качества работы системы оценку релевантности выданных документов производят, как правило, апостериорно. Разумеется, апостериорная релевантность зависит от априорной, однако эти две характеристики различны по своей природе. При автоматическом поиске система может лишь устанавливать степень соответствия поискового предписания поисковым образам документов, что требует введения еще одного параметра - системной релевантности.
Простейший из возможных критериев релевантности -требование полного совпадения поискового образа документа с поисковым предписанием. Разумеется, на практике этот критерий практически неприменим (если речь не идет о поиске издания по полному библиографическому описанию или поиске всех документов в некотором тематическом классе по однозначной классификации знаний). В реальных поисковых системах с их пословным индексированием вероятность полного совпадения предписания с поисковым образом близка к нулю. Поэтому степень релевантности оценивается на основе частичного совпадения поискового предписания с поисковым образом документа, при этом документ считается отвечающим запросу, если степень его релевантности превосходит некоторый установленный в системе порог. Суть всех известных методов вычисления относительной системной релевантности, от простых до самых изощренных - попытки по формальным признакам смоделировать человеческое восприятие сходства и различия смысла текстов.
Степень релевантности может быть оценена как отношение числа найденных в документе дескрипторов запроса A к общему числу дескрипторов в запросе N: R1 = А/N. В практических поисковых системах порог релевантности задают установлением допустимой разницы d между значениями N и A. Если поиск на полное совпадение неудовлетворителен, проводится поиск при d=1,2,: и т.д. Очевидно, что если запрос состоит из одного термина, можно вести поиск только на полное соответствие, также очевидно, что для уменьшения количества выданных документов нужно увеличивать значение A. Присутствие в документе дескрипторов, отсутствующих в запросе, в оценке R1 не учитывается, что может существенно снизить степень фактической релевантности.
С учетом последнего
соображения, за критерий релевантности может быть принята величина R2 = А/М, где M -
общее число дескрипторов в ПОД. Как показывают практические экспертные оценки,
для систем с критерием релевантности R2 удовлетворительные
результаты поиска достигаются при установлении пороговых значений R2![]() [0,25;
0,4]. Очевидна существенная зависимость значения R2 от принятой в системе глубины
индексирования документов и от среднего значения М в поисковом
образе документа. Так, при M=10 и A=1
значение R2 никогда не
превысит 0,1 и ничего не будет найдено. В запрос потребуется
добавить новые термины, уточняющие его формулировку. На практике при пословном
индексировании всего документа современными поисковыми системами и величине A
[0,25;
0,4]. Очевидна существенная зависимость значения R2 от принятой в системе глубины
индексирования документов и от среднего значения М в поисковом
образе документа. Так, при M=10 и A=1
значение R2 никогда не
превысит 0,1 и ничего не будет найдено. В запрос потребуется
добавить новые термины, уточняющие его формулировку. На практике при пословном
индексировании всего документа современными поисковыми системами и величине A![]() [1,3] в большинстве запросов
среднестатистического пользователя удовлетворительная релевантность достигается
лишь на запросах, содержащих низкочастотные термины.
[1,3] в большинстве запросов
среднестатистического пользователя удовлетворительная релевантность достигается
лишь на запросах, содержащих низкочастотные термины.
Два описанных критерия релевантности, как правило, усложняются учетом значимости дескрипторов для документа и для запроса, при условии, что дескрипторам в процессе индексирования присвоены весовые коэффициенты.
Если в документе найдено K дескрипторов запроса с назначенными
им весами пользователя n1,:,nk, а в документе указанные дескрипторы имеют веса
m1,:,mk, то
в качестве критерия релевантности может быть принята величина ![]() , или, для достижения
независимости значения релевантности от масштабов присвоения весов,
, или, для достижения
независимости значения релевантности от масштабов присвоения весов, 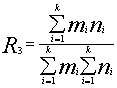 .
.
Как и предыдущие 2
величины, значение ![]() .
.
Для учета возможных рассогласований тематики документа и поисковой потребности пользователя, в формулу оценки релевантности могут быть добавлены члены, уменьшающие ее значение при наличии несовпадающих терминов:
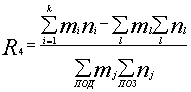
Здесь ml - веса дескрипторов документа, не находящих соответствия в запросе, nl - веса дескрипторов запроса, не находящих соответствия в документе, а суммы в знаменателе дроби ищутся по весам всех дескрипторов ПОД и ПОЗ.
Поскольку значение R4 изменяется от -1 до 1, естественной границей релевантности можно считать R4 = 0, в этом случае суммарный относительный вес отсутствующих дескрипторов не превосходит суммарный относительный вес совпадающих.
Уменьшение релевантности
может выражаться только не путем вычитания весов несовпадающих дескрипторов, но
и делением суммы весов совпадающих на сумму весов несовпадающих дескрипторов.
При этом формула может быть упрощена, приобретая форму, не зависящую от
масштабов присвоения весов и глубины индексирования: 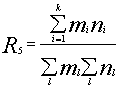 . Однако, значение R5 не нормализовано, естественной границей
релевантности можно считать R5=1.
. Однако, значение R5 не нормализовано, естественной границей
релевантности можно считать R5=1.
Следует подчеркнуть, что от конкретной формулы расчета релевантности, принятой в информационно‑поисковой системе, существенно зависит эффективность поиска. Разумеется также, что приведенными базовыми формулами оценки релевантности не ограничиваются.
Так, крупнейшая в русскоязычном Интернете поисковая машина Яndex использует для оценки релевантности документа запросу аддитивную модель [14], согласно которой показатель релевантности складывается из взвешенных слагаемых, учитывающих встречаемость слов из запроса в документе, встречаемость пар слов, встречаемость текста запроса целиком, наличие всех слов запроса в документе и наличие многих слов запроса в одном предложении. После этого, на втором этапе поиска производится оценка релевантности документов, отобранных на первом этапе. Подобную аддитивную модель использует и поисковая система Mail.Ru [15].
Существует множество вариаций выбора стандартного слагаемого, отвечающего за встречаемость слова в тексте, основанных как на ставшем классическим алгоритме BM‑25 [16], так и на реже используемых алгоритмах pl2, bm3 и других [17]. Подобный подход известен как "модель TF*IDF", различные его варианты описаны, например, в [18].
Как показывает опыт [14, 15], оптимальными на сегодняшний день являются модифицированные версии алгоритма BM‑25. Согласно алгоритму, величина, отвечающая за релевантность, рассчитывается по формуле
![]() , где TF -
число вхождений дескриптора в документ, DL - общее
количество дескрипторов в документе (при использовании не обработанных
синтаксически "слов" вместо дескрипторов результативность поиска
существенно ухудшается). Использование в качестве меры длины документа
максимальной TF среди всех
дескрипторов документа также существенно ухудшает результат. В качестве p используются такие величины как
, где TF -
число вхождений дескриптора в документ, DL - общее
количество дескрипторов в документе (при использовании не обработанных
синтаксически "слов" вместо дескрипторов результативность поиска
существенно ухудшается). Использование в качестве меры длины документа
максимальной TF среди всех
дескрипторов документа также существенно ухудшает результат. В качестве p используются такие величины как
![]() ,
, ![]() ,
, ![]() , где D - число
документов в коллекции, DF - количество
документов, в которых встречается дескриптор, CF -
число вхождений дескриптора в коллекцию, TL - общее
число вхождений всех дескрипторов в коллекции. Известны также модификации приведенных
формул на основе нелинейных преобразований DL и поиска наилучших поддокументов в составном документе [19].
На практике наилучший из приведенных вариантов результат показывает критерий ICF [14].
, где D - число
документов в коллекции, DF - количество
документов, в которых встречается дескриптор, CF -
число вхождений дескриптора в коллекцию, TL - общее
число вхождений всех дескрипторов в коллекции. Известны также модификации приведенных
формул на основе нелинейных преобразований DL и поиска наилучших поддокументов в составном документе [19].
На практике наилучший из приведенных вариантов результат показывает критерий ICF [14].
Приведем в качестве примера также процедуру расчета релевантности, используемую в американских ИПС Министерства обороны еще с 50‑х гг. XX века. При этой процедуре для каждого термина запроса просматривался весь имеющийся массив документов, подсчитывалась частота совместной встречаемости данного термина со всеми другими. Далее для каждого термина составлялся упорядоченный список терминов, совместно встречающихся чаще, чем в среднем (связанные термины). Далее из всех профилей терминов запроса выбираются общие для всех них. С отобранными терминами процедура повторяется. На основе частоты совместной встречаемости терминов этого списка вычисляется их вес (чем больше связанность, тем выше вес). Наконец на основе этих весов рассчитывался показатель релевантности аналогичный R3.
Как уже указывалось выше, современные информационно‑поисковые системы, такие, как Яndex, для повышения качества отбора релевантных документов активно используют аддитивные модели определения релевантности и эшелонирование выдачи, при котором в качестве результатов поиска сначала выдаются отобранные аддитивной формулой документы с высокой релевантностью, а затем дополнительно оценивается релевантность документов, найденных на первом этапе. Впервые идея подобной системы с встроенным ИПТ, предназначенным для выявления смысловых связей слов, была реализована в ИПС с названием "Пусто-непусто", разработанной ВИНИТИ и внедренной в ЦНТИ "Информэлектро". Ведущие разработчики - В. М. Чернявский, Э. С. Бернштейн и Д. Г. Лахути [20]. Кратко остановимся на данной концепции и перспективах ее развития.
Название системы обусловлено принятым в ней критерием релевантности, определяющимся соотношением наполненности четырех множеств:
М1 - множество дескрипторов, совпадающих в ПОД и ПОЗ;
М2 - множество дескрипторов ПОД, родовых для дескрипторов ПОЗ;
М3 - множество дескрипторов ПОД, видовых для дескрипторов ПОЗ;
М4 - множество дескрипторов ПОД, не связанных с дескрипторами ПОЗ.
По соотношению пустоты и наполненности этих множеств можно ранжировать и выбирать конкретный критерий выдачи документов. Наиболее вероятна релевантность документа, если все его дескрипторы совпадают с запросом:
|
М1 |
М2 |
М3 |
М4 |
|
совпадающие |
родовые |
видовые |
Посторонние |
|
+ |
0 |
0 |
0 |
Столь же вероятна релевантность, если в документе есть также видовые дескрипторы, возможно, наряду с родовыми:
|
+ |
0 |
+ |
0 |
|
+ |
+ |
+ |
0 |
Эти документы составляют первый эшелон выдачи. Если в документе есть только видовые дескрипторы, это может означать, что в нем идет речь только о части понятий, интересующих пользователя. Документы с заполненным только М3:
|
0 |
0 |
+ |
0 |
составляют второй эшелон выдачи.
Если в документе представлены родовые (обобщающие) понятия, это может означать, что содержание его касается преимущественно общих понятий, а конкретный интересующий пользователя дескриптор упоминается лишь как частность. Документы с заполненным М2 составляют третий эшелон выдачи:
|
+ |
+ |
0 |
0 |
|
0 |
+ |
0 |
0 |
|
0 |
+ |
+ |
0 |
Документы, содержащие "посторонние" дескрипторы множества М4 (М4 ≠ 0) в реализации системы "Пусто‑непусто" не участвуют в выдаче, возможно, это можно оценить как недостаток реализации. Общая таблица эшелонов выдачи такова:
|
Эшелон |
М1 |
М2 |
М3 |
М4 |
|
|
совпадающие |
родовые |
видовые |
посторонние |
|
|
+ |
0 |
0 |
0 |
|
1 |
+ |
0 |
+ |
0 |
|
|
+ |
+ |
+ |
0 |
|
2 |
0 |
+ |
0 |
0 |
|
|
+ |
+ |
0 |
0 |
|
3 |
0 |
+ |
0 |
0 |
|
|
0 |
+ |
+ |
0 |
В приведенном примере особенно существенно то, что для определения соответствия документа запросу использованы знания логических связей понятий, заложенные в ИПС и представляющие собой модель предметной области, в которой работает система. Представляется перспективным развитие данного подхода как в разработке автоматизированных систем вообще, так и ИПС в частности.
Вторая существенная особенность рассмотренной системы, уже ставшая стандартом для современных ИПС - эшелонированная выдача: документы с малой степенью релевантности не отсекаются, но пользователю предлагается сначала получить высокорелевантные документы, а затем продолжать знакомство с результатами поиска, информационная потребность не будет удовлетворена или пользователь не обнаружит, что в последующих документах нет пертинентной информации. Фактически, при указанном подходе пользователь сам устанавливает требуемый критерий релевантности в процессе диалога с системой. Представляется перспективным такое развитие этого подхода, как использование в создаваемых ИПС нескольких альтернативных критериев релевантности для повышения качества профессионального поиска.
Следует отдельно остановиться на том, как пользователь может оценить полезность и техническую эффективность ИПС. Степень технической эффективности может быть определена сравнением реальной действующей ИПС с идеальной моделью. Основоположник научно‑технической информатики К. Муэрс дал следующее "неформальное" определение идеальной модели: это система, которая из документального фонда выдает ровно те и только те документы, которые отобрал бы сам пользователь при внимательном прочтении каждого из них. Разумеется, данное определение лишено практической ценности, поскольку пользователь судит о системе по ее реальной пертинентности, которая заведомо ниже технической релевантности.
Соотношение множества реально выданных документов Мр с множеством идеальной выдачи Ми характеризуется следующими подмножествами (рис. 1):
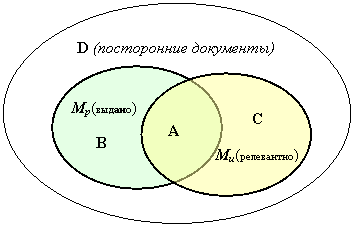
Рис 1. Соотношения реальной и идеальной выдачи
А - документы, реально выданные системой и входящие в желаемую выдачу, А = Мр ∩ Ми ;
В - документы, выданные системой, не входящие в желаемую выдачу, В = Мр ∩ Ø Ми ;
С - документы, не выданные системой, но входящие в желаемую выдачу, С = Ø Мр ∩ Ми ;
D - документы, не входящие ни в реальную, ни в желаемую выдачу D = Ø Мр ∩ Ø Ми .
В случае "идеальной" выдачи Мр= Ми = А, В = С = D = 0
Реальный случай может апостериорно характеризоваться соотношением числа документов в указанных множествах. Пусть na - число документов в множестве А, nb - число документов в В и так далее. Наиболее популярны следующие отношения:
Коэффициент
точности ![]() определяется
как отношение числа релевантных документов в результатах поиска к общему числу
документов в выдаче.
определяется
как отношение числа релевантных документов в результатах поиска к общему числу
документов в выдаче.
Коэффициент
полноты ![]() определяется
как отношение числа релевантных документов в выдаче к общему числу релевантных
документов в индексе.
определяется
как отношение числа релевантных документов в выдаче к общему числу релевантных
документов в индексе.
Множество В, содержащее
документы выдачи, не соответствующие запросу, называется шумом.
Относительное количество "шумовых" документов в выдаче ![]() называется коэффициентом
шума, T+N=1.
называется коэффициентом
шума, T+N=1.
Множество С содержит "потери" -
релевантные документы, не выданные пользователю. Аналогично рассмотренным выше
коэффициентам, отношение числа "потерянных" документов nc к общему
числу релевантных документов в индексе может быть названо коэффициентом
потерь (распространено также название "коэффициент молчания")
![]() , P+L=1.
, P+L=1.
Очевидно, что чем выше коэффициенты полноты и точности, тем эффективность поиска выше. На практике при работе с ИПС возможны различные значения T и P для различных запросов, поэтому об эффективности системы судят по среднему арифметическому показателей T и P для большого числа поисковых сессий. Таким образом, усредненный коэффициент P характеризует вероятность того, что некоторый релевантный документ в индексе будет выдан по запросу, а коэффициент Т - вероятность того, что некоторый документ в выдаче окажется релевантным.
Существенно то, что полнота и точность поиска зависят не только от системы, но и от типа запросов, например, система может оказаться более или менее релевантной в выдаче на низкочастотные и высокочастотные запросы. Поэтому при указании характеристик системы следует указывать условия проведения испытаний и характер запросов, на основании которых эти характеристики были вычислены.
Полнота и точность являются независимыми характеристиками ИПС. Тем не менее, существует эмпирически выявленные ограничения на эти показатели у практически работающих ИПС, ни полнота, ни точность выдачи которых никогда не достигают 100%. Как правило, попытки за счет изменения условий работы или критерия выдачи ИПС повысить один из этих показателей приводят к падению значения другого, что наглядно видно на примере эшелонирования выдачи.
При ограничении выдачи первым эшелоном, содержащим документы с наибольшим априорным показателем релевантности, в выдаче оказывается достаточно много действительно релевантных и достаточно мало фактически шумовых документов, т. е. точность T высока. Однако в выдаче при этом отсутствует достаточно большое количество документов с меньшим показателем релевантности, но высокой пертинентностью с точки зрения пользователя, то есть полнота выдачи P низка. Принятие в выдачу последующих эшелонов документов приводит к повышению полноты P, но при этом в выдачу попадает множество малорелевантных документов, т. е. снижается показатель T.
Типовое соотношение полноты и точности характеризуется обратной зависимостью и может быть показано на следующем типичном для известных систем графике (рис. 2).
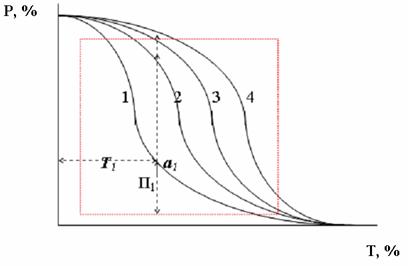
Рис 2. Зависимость между достижимыми показателями P и T
По координатным осям отложены значения коэффициентов точности и полноты в процентах, а точки четырех кривых показывают значения коэффициентов полноты и точности для четырех различных ИПС. Так, точка а1 показывает, что первая система в режиме, обеспечивающем 40% точности выдает лишь 30% релевантных документов, а третья система при той же точности - около 90% релевантных документов, имеющихся в индексе. Чем выше проходит график показателей системы, тем выше ее эффективность. Крайние точки графиков практически недостижимы, обычно реальные системы не выходят за пределы, приблизительно указанные на рисунке пунктирным квадратом.
Для интегральной оценки эффективности ИПС широко используется показатель эффективности E=P+T. Считается, что эффективность ИПС приемлема, если E приближается к 1.
Имеет смысл и показатель E2=P*T. Он позволяет оценить действие системы в центре диапазона работы, где для эффективной ИПС он должен принимать значения около 0,5. В нашем примере это выполняется для четвертой системы.
Указанные показатели не
учитывают весьма важное с практической точки зрения обстоятельство - объем
поискового индекса. Очевидно, что отыскать необходимые документы среди большого
числа "шумовых" значительно труднее, чем в случае, когда большинство
документов в индексе релевантны. Для оценки способности системы к отсеиванию "шумовых"
документов существует коэффициент селективности (специфичности) S, равный отношению числа невыданных нерелевантных документов
к общему числу нерелевантных документов в индексе: ![]() , где nd -
мощность множества D.
, где nd -
мощность множества D.
Максимальное значение S=1 достигается при отсутствии в выдаче шумовых документов, т. е. при Т = 1, N = 0. При одной и той же точности T показатель S тем выше, чем меньше в индексе релевантных документов. В этом смысле коэффициент S наиболее объективно оценивает работу самого механизма ИПС.
В практически важных случаях перечисленные показатели не могут быть определены с достаточной точностью, прежде всего потому, что на практике неизвестно число невыданных релевантных документов nc.
С
неизбежной погрешностью может быть определено лишь относительное содержание
релевантных документов в массиве 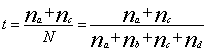 , опытным путем трактуемое как
вероятность получения релевантного документа при случайном выборе документов из
индекса поиска. В этом случае величина nc
может быть определена через вероятность t по формуле
, опытным путем трактуемое как
вероятность получения релевантного документа при случайном выборе документов из
индекса поиска. В этом случае величина nc
может быть определена через вероятность t по формуле ![]() , где значение N предполагается известным с достаточной точностью, а
коэффициенты S и P принимают вид
, где значение N предполагается известным с достаточной точностью, а
коэффициенты S и P принимают вид ![]() ,
, ![]() .
.
Однако, указанный способ вычисления показателей эффективности также не всегда применим, например, объем поискового массива Интернета не может быть оценен с приемлемой точностью. Поэтому для ИПС, работающих в Интернет, показатели полноты и селективности поиска остаются слабо определенными.
Поскольку
показатель точности также требует соотнесения с общим характером поискового
массива, работу ИПС на практике характеризует не столько сама точность, сколько
улучшение точности по сравнению со случайным выбором документов. Для
оценки этого показателя может использоваться "коэффициент уточнения"
![]() , равным
отношению коэффициента точности к вероятности случайного документа в массиве
оказаться релевантным. Иными словами, коэффициент U
показывает, насколько концентрация релевантных документов в выдаче превосходит
концентрацию их в индексе.
, равным
отношению коэффициента точности к вероятности случайного документа в массиве
оказаться релевантным. Иными словами, коэффициент U
показывает, насколько концентрация релевантных документов в выдаче превосходит
концентрацию их в индексе.
Применяются и другие коэффициенты, учитывающие относительную важность выдачи релевантных и нерелевантных документов, но большинство из них носит либо сугубо субъективный, либо узко специализированный характер.
|
|